
Stream Processing
Stream Processing is a method of tracking and analyzing streams of information of an event, and eventually obtaining useful structured conclusions out of that raw information.
Altair's CEP engine is named Panopticon Streams and it is built so that it can cooperate with different CEP engines.
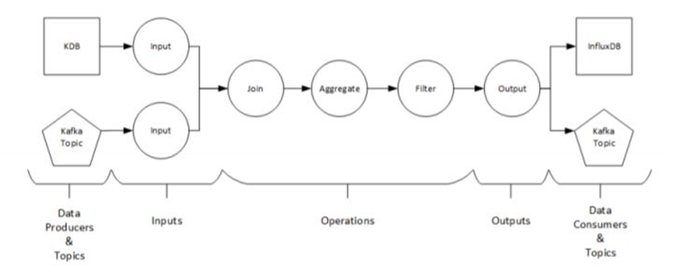
The main task of the Panopticon Streams is to execute and manage streams applications. An application describes how data should be piped, transformed, and processed. Applications consist of a set of inputs, operators, and outputs that can be viewed as a directed graph with a set of nodes (or operators) and a set of edges (or streams) that are interconnected with each other.
Panopticon Streams Operators
- Aggregation
- The aggregation operator aggregates the data based on a grouping key and a set of aggregated fields.
- Branch
- The branch operator will split a stream into one or more branches. The path for a stream is determined by a configured predicate within the branch operator.
- Calculation
- The calculation operation will calculate a field and add the result as an additional field. Usually, input fields pass through an operation, but calculations can also be set to replace existing fields or simply remove them.
- Conflate
- The conflate operation is used to lower the frequency of updates. The conflate will retain the last records seen on the input and push them to the output stream on a fixed interval. For example, if the input is producing a high frequency data throughput, instead of processing all of these updates, a configured conflate will only push through a small set of records on a fixed interval.
- External Input
- Sources data directly from a Kafka topic.
- Filter
- Used to filter a data source based on a predicate.
- Input
- Used to define the input data for the application model.
- Join
- Used to join data sources using common keys.
- Metronome
- Similar with a synthetic input, this operator acts as a single timestamp field schema generator.
- Rank
- Assign a rank number to records in the same group.
- Rekey
- Takes a stream data and changes its key. The new key can be any subset of fields from the stream.
- Scatter
- Given a record with array fields (must have the same length), the scatter operator will emit one record for each position in the array(s). This operator is similar with unpivot but on array positions instead of columns.
- To_Stream
- Aggregating on delta as a Table causes a change log, producing a single record. The Table to Stream operator morphs the single record back into stream.
- Output
- An output produces and publishes streams towards a Kafka topic or a data consumer.
- Union
- Used to perform a union of two streams. Both streams would need the same schema. Otherwise, the output would be the combination of both, with missing values returned as Null.
- Python Transformation
- A Python script can be executed as a data transformation step in the data pipeline.
- REST Transformation
- Takes an input data frame, executes a REST call, and interprets the result which gets passed upstream.
- R Transform
- An R script can be executed as a data transformation step in the data pipeline.
Watch the video below for more information about Stream Processing:
Panopticon Streams Inputs
The Panopticon Streams engine allows the combination of multiple data sources and their definition as input channels. The data sources are referred to within the Panopticon Streams as inputs. The data produced by each input can be processed by one or more operators.
Panopticon Streams Outputs
An output produces and publishes streams towards a Kafka topic or a data consumer. A data consumer is the opposite of a data producer. It consumes the data produced from an output in Panopticon Streams and publishes the data to a data source.
Find below an example about how to create an input datasource, an output datasource and a simple application.